

In the modern landscape of application development, the friction between Object-Relational Mapping (ORM) paradigms and relational database efficiency has become a defining challenge for database administrators and backend engineers. At the heart of this friction lies the "polymorphic association"—a ubiquitous design pattern where a single table holds a reference to various other tables, often via a discriminated foreign key (a (type, id) pair).
While this pattern allows developers to build flexible systems—such as activity feeds in CRMs or dynamic product catalogs in e-commerce—it introduces a significant "performance tax." As the number of subtypes increases, the database optimizer is forced to perform a series of LEFT JOIN operations that are inherently inefficient. Recent discussions on the pgsql-hackers mailing list have brought this issue to the forefront, signaling a potential shift in how PostgreSQL handles these complex, sub-optimal query patterns.
The Anatomy of a Performance-Hostile Pattern
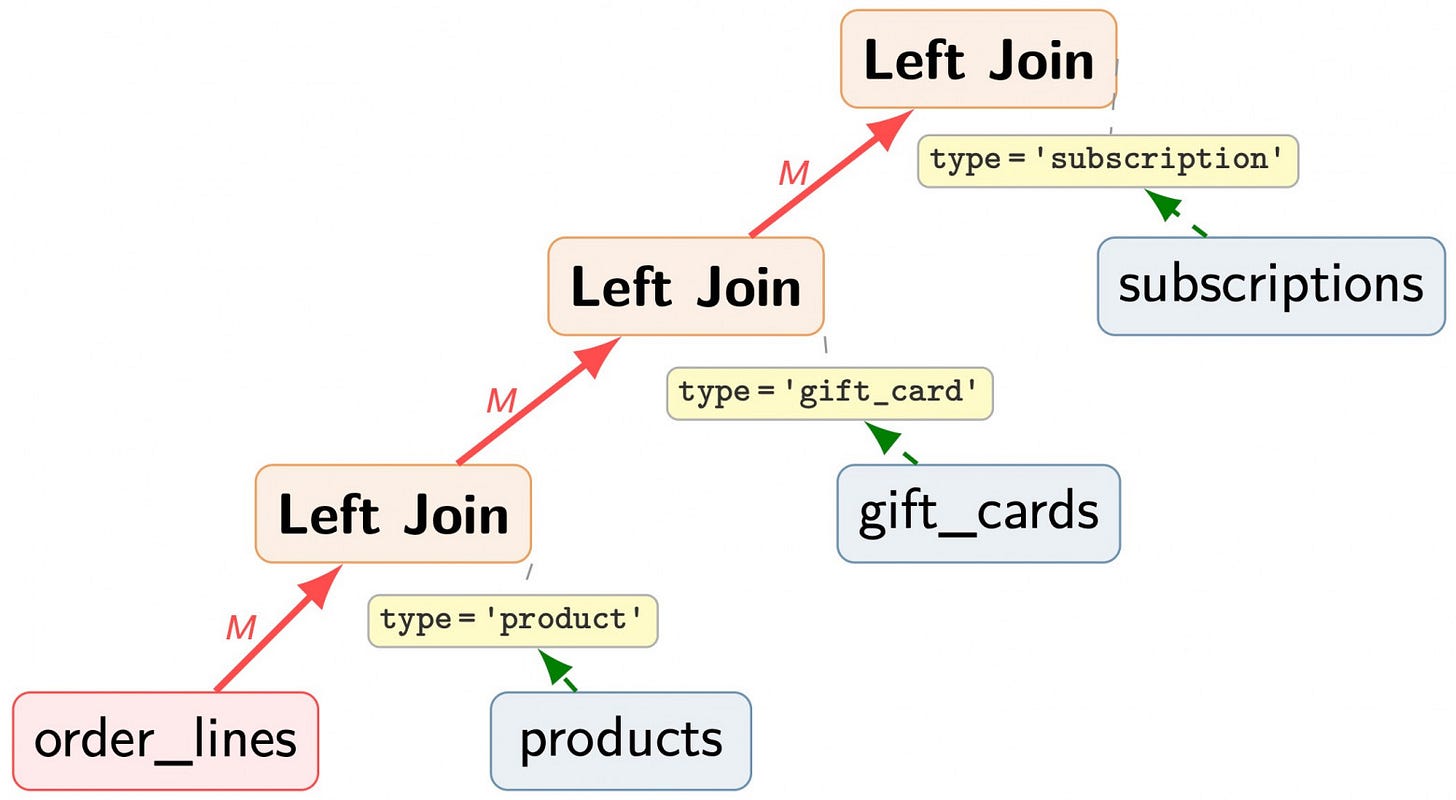
Polymorphic associations are the bread and butter of modern web frameworks. Whether you are working with Rails, Django, Hibernate, or complex enterprise platforms like Salesforce and 1C, the ORM frequently defaults to this pattern to handle "belongs_to" relationships where a single column must point to multiple potential parent tables.
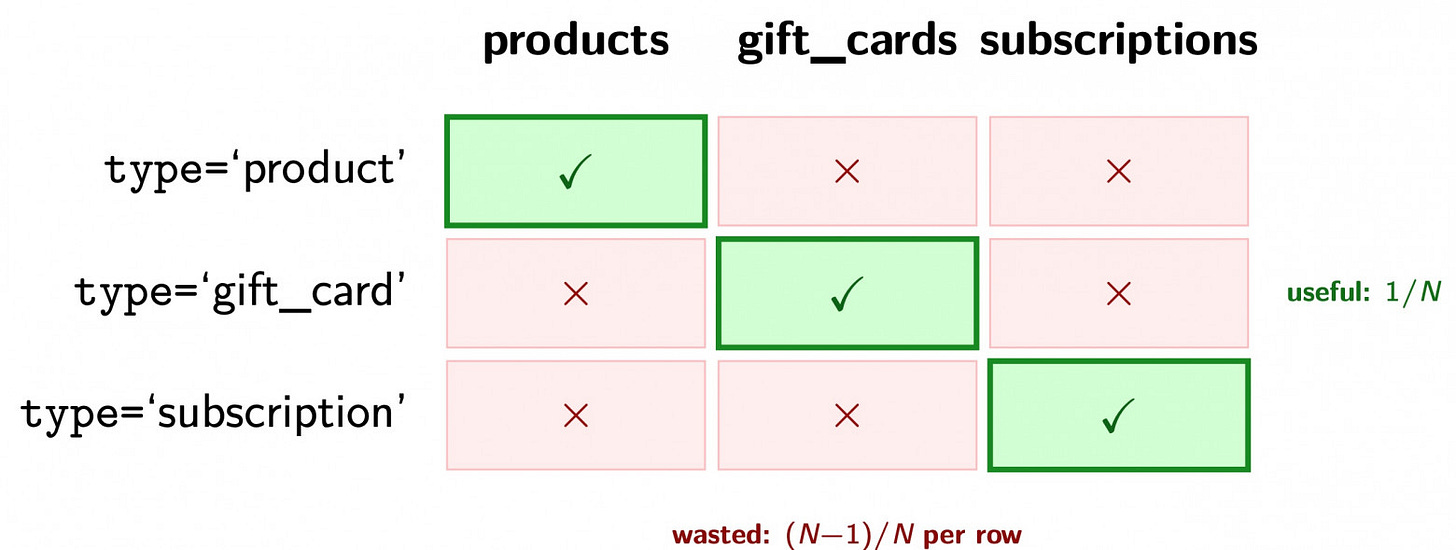
The query structure typically looks like this: a base table (e.g., order_lines) is LEFT JOIN-ed to every possible subtype table. For a row in the base table, the query probes every potential candidate. The irony of this approach is that, in any given row, only one join will return a match—the one dictated by the discriminator. The remaining $N-1$ joins are guaranteed to return NULL, yet the database must still expend the computational effort to probe them.
Currently, the PostgreSQL optimizer treats these joins with primitive logic: it selects a fixed scan order for the inner side of the LEFT JOIN and applies it blindly to every row. Because there is no schema-level guarantee that key values across these inner tables are non-overlapping, the optimizer cannot safely "route" the query to the correct table. The baseline cost is $O(M times N)$ probes, where $M$ is the number of rows in the base table and $N$ is the number of subtypes. Only $O(M)$ of these probes are productive, leaving the remaining $O(M times (N-1))$ as pure overhead.
A Chronology of Proposed Optimizations
Throughout 2024, 2025, and into 2026, the PostgreSQL community has engaged in rigorous debate regarding how to alleviate this performance bottleneck. The discourse has crystallized into three primary technical strategies, each targeting a specific source of regression.
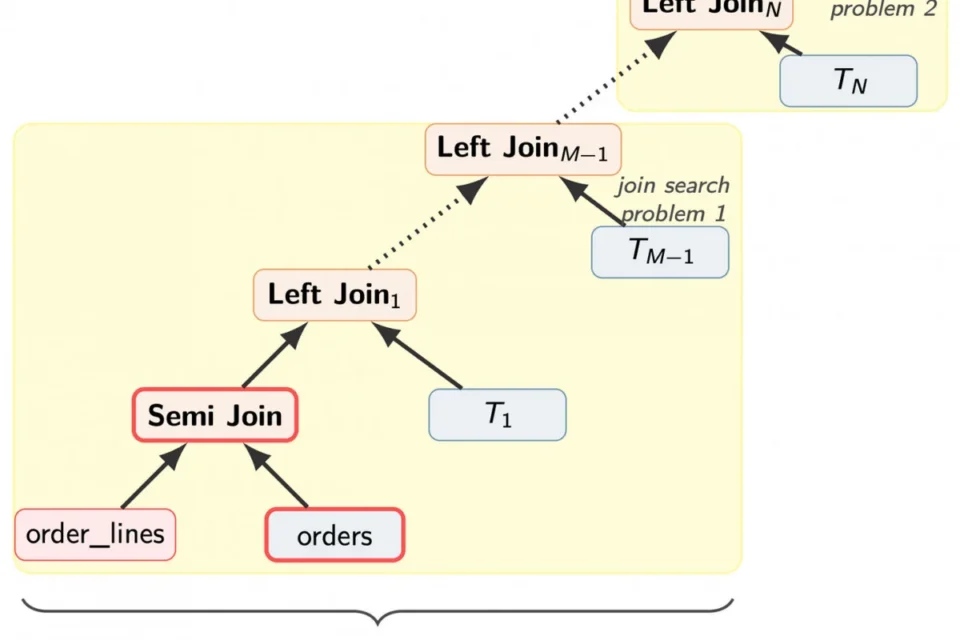
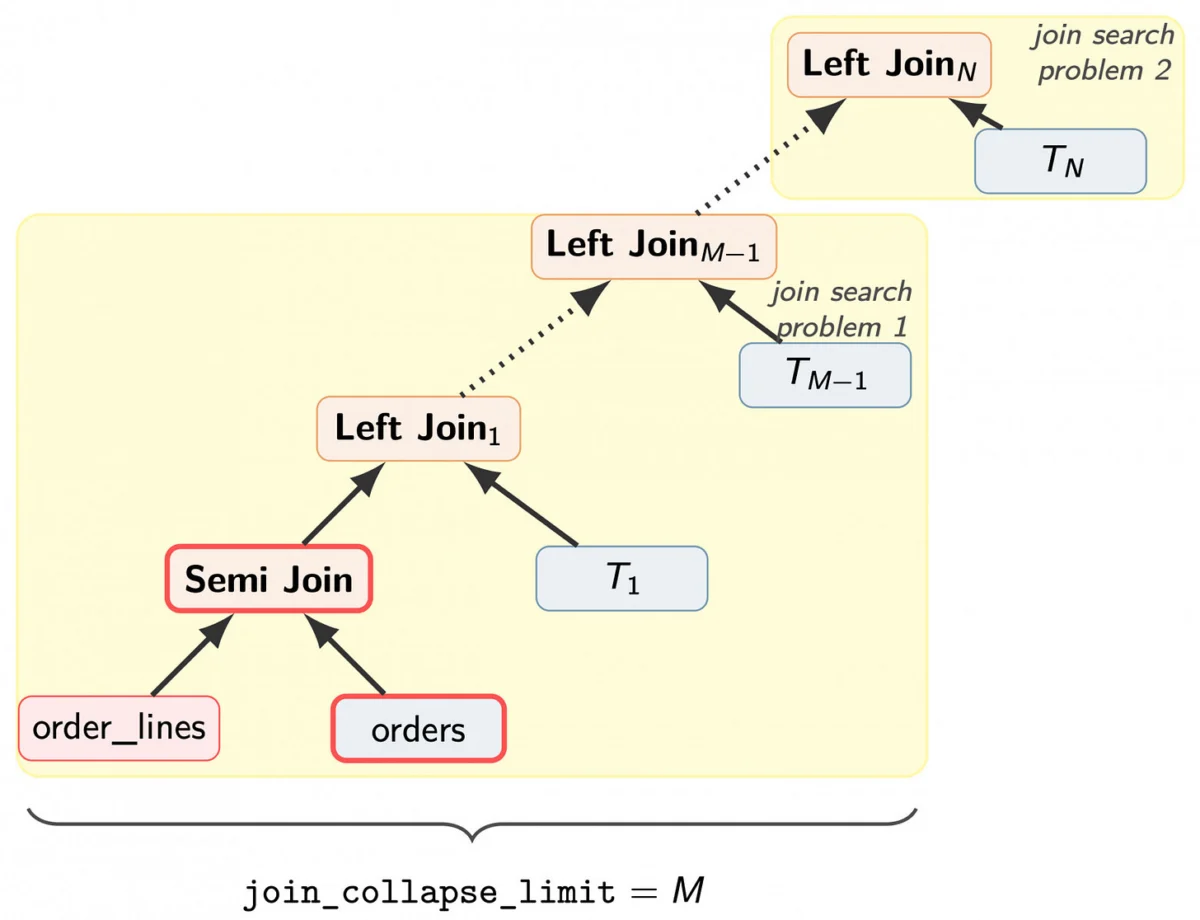
1. The Gating Operator (December 2024)
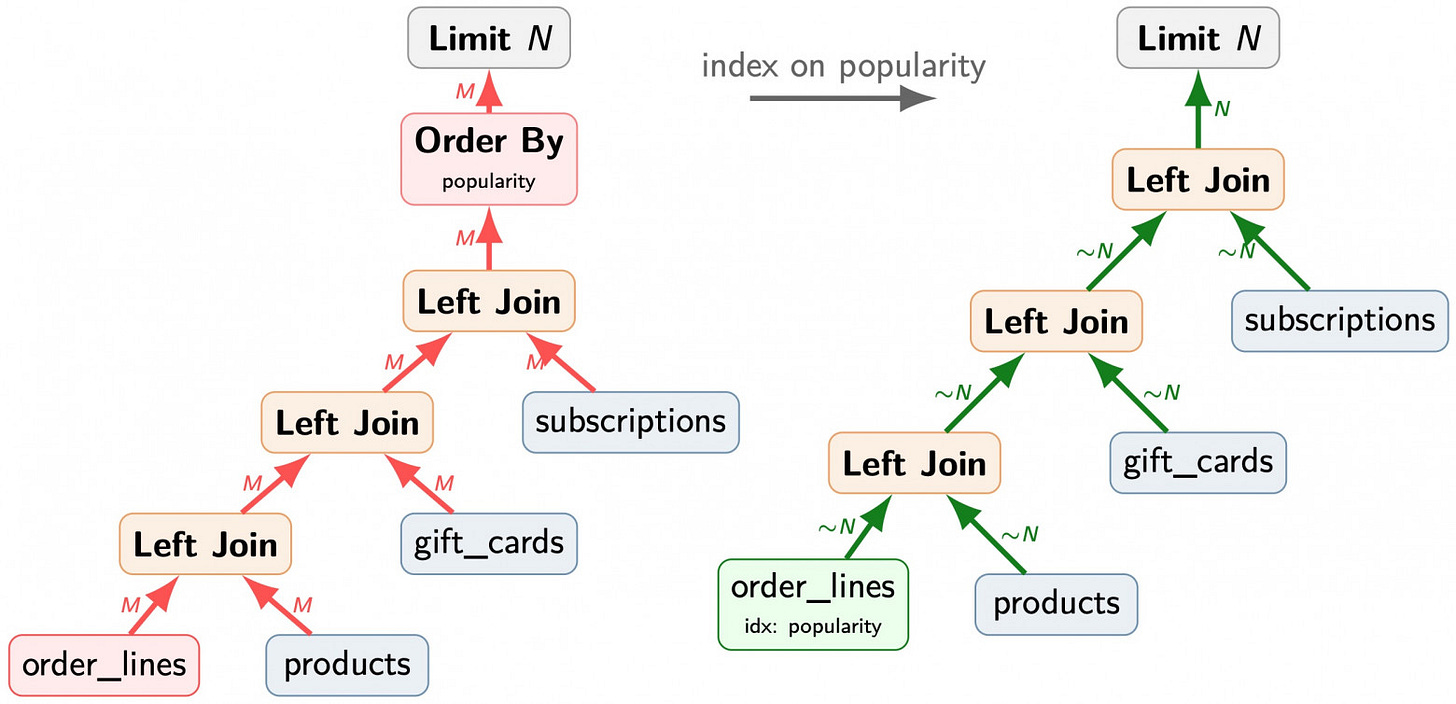
In late 2024, a thread on pgsql-hackers titled "Do not scan index in right table if condition for left join evaluates to false" gained significant traction. Tom Lane proposed a method to split JOIN ... ON conditions into two distinct groups: those depending solely on the outer table and those requiring the inner table.
Andres Freund refined this by suggesting the implementation of a "gating operator"—a specialized Result plan node. By evaluating the discriminator condition on the outer row before triggering the inner scan, the database can effectively "gate" the join. If the condition is false, the engine skips the inner scan entirely. While this doesn’t eliminate the join, it reduces the overhead to negligible levels, as the gating expression does not require access to disk or shared buffers.
2. Sort Pushdown for Query Efficiency (April 2026)
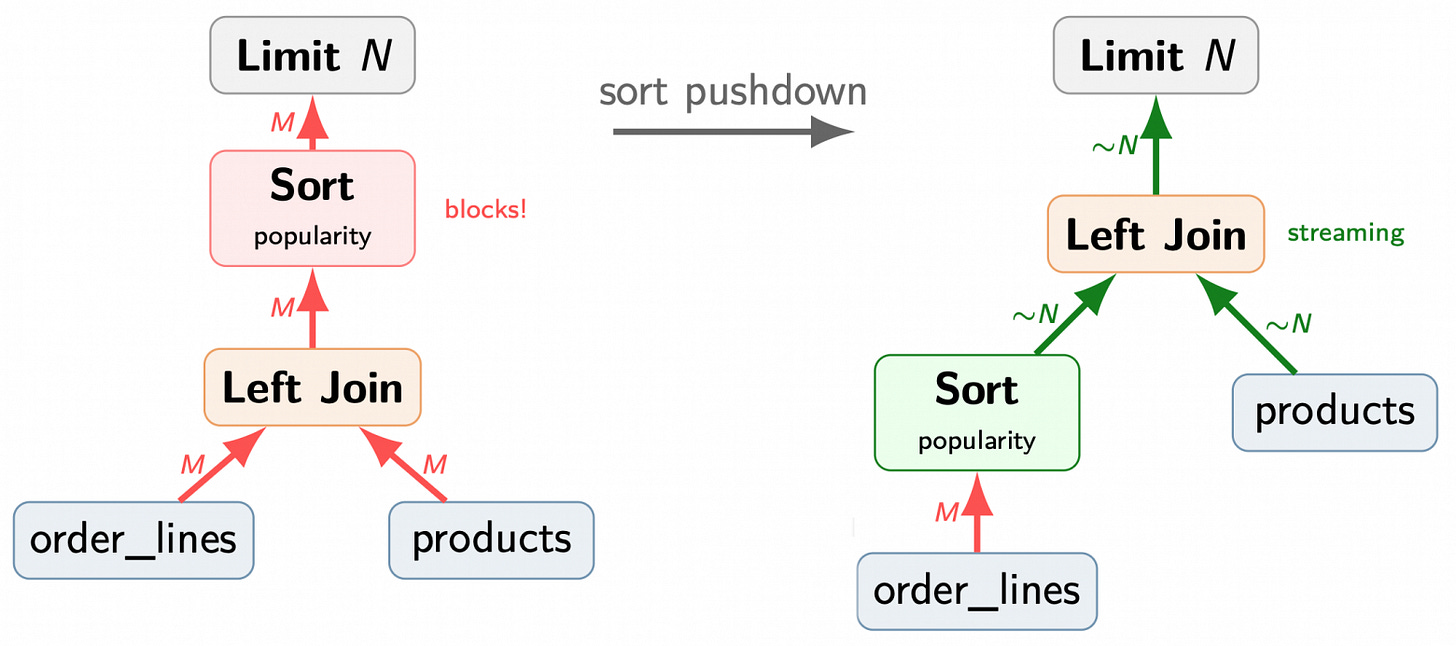
A second major issue arises with ORDER BY and LIMIT constructs, which are essential for features like "Top-N" product lists. If the base table is not naturally sorted by the requested column, the database is often forced to pass every row through the entire join tree before performing a sort at the very top of the execution plan.
A proposal from April 2026 suggests enabling the optimizer to build a pre-sorted path for the base table if that table is mentioned in the prefix of the query_pathkeys. By pushing a sort operation (such as a heapsort or Top-N sort) directly above the base-table scan, the database avoids pushing massive amounts of data through the join tree. This "Sort Pushdown" technique prevents the performance cliff typically seen as the join tree grows in complexity.
3. Subquery-to-JOIN Transformation (May 2026)
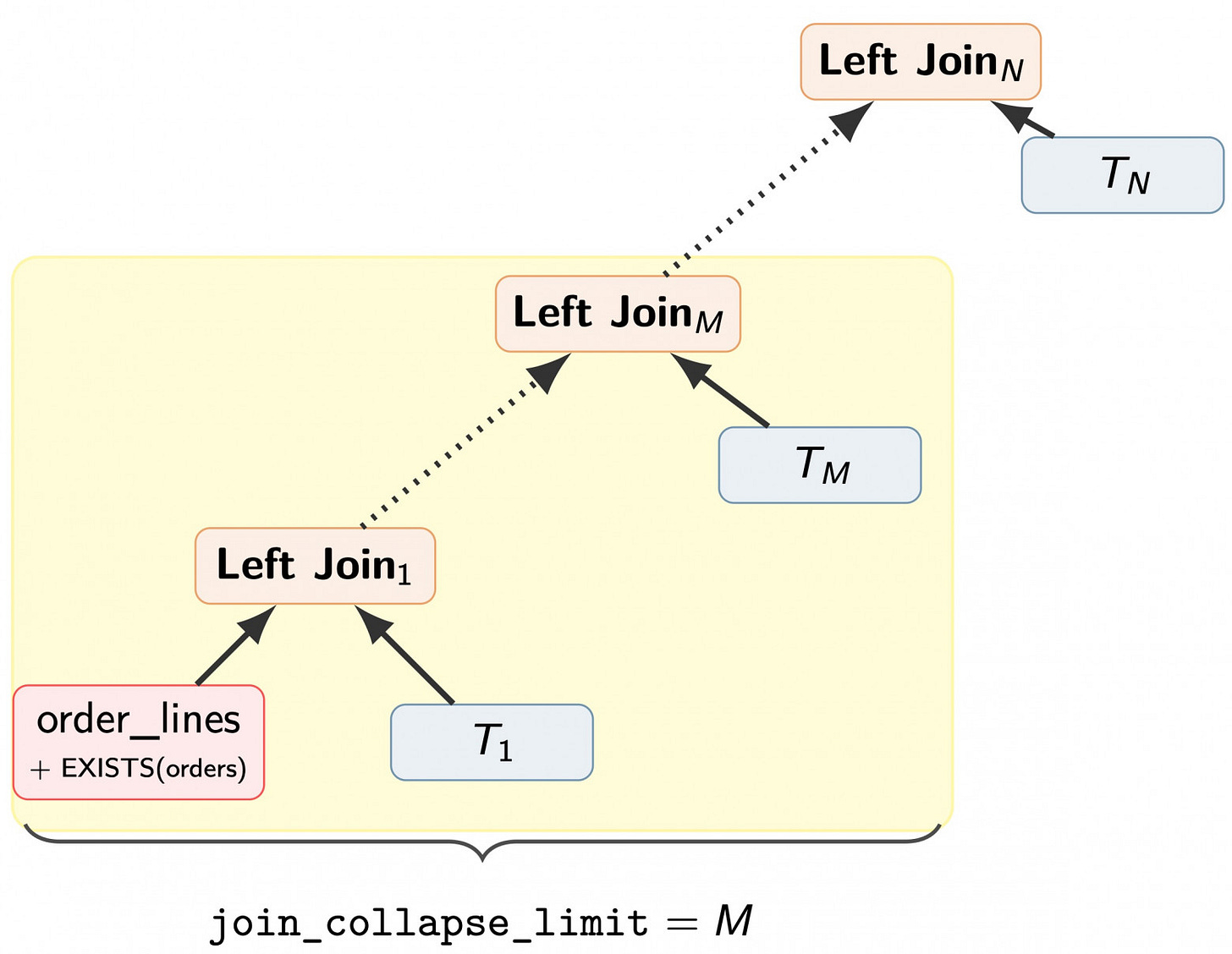
Finally, the handling of EXISTS clauses presents a unique challenge. When an EXISTS subquery cannot be transformed into a join, it acts as a powerful filter, significantly reducing the row count before it hits the join tree. However, if the optimizer successfully transforms it into a SEMI JOIN, it often places that join at the top of the tree, potentially negating the filtering benefits.
The May 2026 patch proposes a "pushdown" logic: once an EXISTS is converted to a SEMI JOIN, the optimizer should place it as low as possible in the join tree—ideally right next to the base table. This ensures that the early filtering power of the subquery is preserved, dramatically reducing the work required by subsequent joins.
Supporting Data and Technical Implications
The impact of these proposed changes cannot be overstated. In production environments where polymorphic patterns involve $N > 10$ joins, the current optimizer behavior can lead to exponential latency growth.
The "Join Selectivity" Frontier
Beyond the three primary patches, Alexandra Wang has introduced a promising prototype concerning "join selectivity statistics." Traditionally, optimizers estimate join selectivity using individual table statistics, which often fails to capture the correlation (skew) between joined columns. By allowing users to declare extended statistics specifically for join results via CREATE STATISTICS, the optimizer can make more informed decisions about whether to use a Nested Loop or a Hash/Merge Join.
While still a proof-of-concept, this approach addresses a fundamental weakness in current query planning. The challenge remains in how to store these statistics in the system catalog to ensure they are useful for multi-table joins without overwhelming the metadata storage.
Implications for System Architects
The push for these optimizations reflects a broader shift in database engineering: the realization that while ORMs are indispensable for development velocity, they create "abstracted" database schemas that are often at odds with the relational model’s strengths.
For the developer, these improvements suggest that the future of PostgreSQL is leaning toward a more "aware" optimizer. Rather than forcing developers to flatten their schemas—a task that is often prohibitively expensive due to legacy code and migration risks—the community is aiming to make the database smart enough to recognize and optimize the "polymorphic tax."
However, it is crucial to note that none of these patches are "silver bullets." They are tactical improvements designed to remove specific pain points. The architectural reality remains: the more complex the polymorphic association, the higher the risk of performance degradation.
Conclusion and Call to Action
The evolution of PostgreSQL is a testament to the community’s commitment to bridging the gap between high-level application abstractions and low-level performance. As of mid-2026, the proposed solutions for gating operators, sort pushdowns, and semi-join optimizations are still undergoing peer review on pgsql-hackers.
For those operating large-scale systems currently struggling with the weight of hundreds of polymorphic LEFT JOIN operations, these developments offer a glimpse of relief. The community encourages developers working with these specific workloads to participate in the ongoing discussions. By providing real-world telemetry and use cases, practitioners can help shape these patches into robust, production-ready features, ensuring that the next generation of PostgreSQL continues to thrive under the demands of modern, object-oriented application design.
As we look toward the future, it is clear that while we cannot fully escape the complexity of our data models, the tools we use to query them are becoming significantly more sophisticated. The "performance tax" may soon be a thing of the past.
